Pascal-M 2K1
Pascal-M Compiler Linker Disassembler Loader system
Hans Otten, November 2021 Version 0.9
Applicable license: MIT license. Permission given by Mark Rustad.
Note that this version is still beta quality! Your feedback is appreciated!
Contents
Downloads for Windows, Ubuntu and Raspberry PI OS:
Pascal-M 2K1 programs
Pascal-M 2K1 sources
How the Pascal-M system works
The Pascal-M system will let you write Pascal programs and execute them on the 6502, e.g. the KIM-1 or the console of the PC.
The Pascal dialect is standard Pascal (no reals for example) as described in the second edition of ‘The Pascal User Manual and Report’. It can (could in older versions!) compile itself.
To get a Pascal program running on the KIM-1 the Pascal-M 2K1 system requires the following steps.
- Edit Write the text of the Pascal program
- Compile Repeat 1 and 2 until no compilation errors
- Load Convert the object M-code of the compiler output to binary code
- Link Combine the compiled binary and the 6502 interpreter to an executable KIM-1 program
- Run Load the Papertape file on the KIM-1 and run it
How to use
Step 1: Write a Pascal program with any text editor on your PC, create ASCII text files.
Save the Pascal source with extension .pas, and keep the editor open. I use Notepad++ on Windows, any editor will do.
Step 2 – 4: Start the PascalM2K1 program, a GUI program, and fill in the name of the Pascal source.
Press Compile and if the Pascal-M compiler sees no errors goto step 3 and press Load else go back to the editor.
Note the load address is needed to tell where the code should go in memory, the default is fine for now.
See the section on ‘Memory layout’.
Step 4 requires to fill in the name of the binary of the 6502 interpreter (default pascalmint2k1.bin, make sure it is found).
Also fill in the name you want for the 6502 program (Binary, a papertape version is produced also).
Fill in the upper memory RAM limit in your KIM-1. the default is for 32K RAM above $2000, max is $9FFF.
Press Link.
Step 5: Take the papertape file via a terminal emulator to the KIM-1 (in TTY mode) and run it from start address $2000
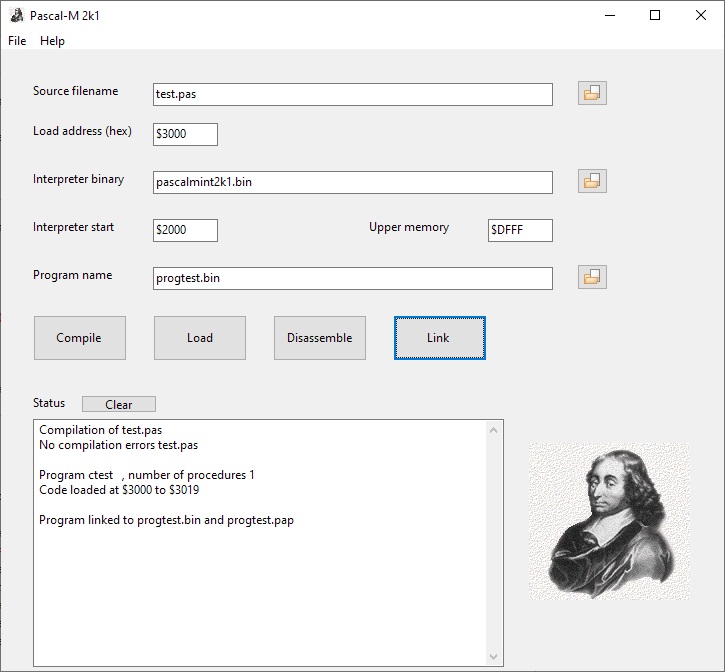

The example file test.pas contains the source:
program ctest ;
begin
writeln('hello world') ;
end.
During the steps of PascalM2k1 many files are produced. If for example you start with helloworld.pas and finally link to runhelloworld.bin the following files will be present:
- helloworld.pas The Pascal source program you have written
- helloworld.lst Listing of the source program with compilation results
- helloworld.obp Px code representation of the Mcode
- helloworld.err Every step produces a file with the status, error or success.
Also shown in the status field in PascalM2k1
- helloworld.bin The Mcode loaded into a binary
- helloworld.prc The Procedure table binary
- helloworld.dlst The disassembled Mcode, see the Debug section
- runhelloworld.bin The runnable program binary
- runhelloworld.pap The MOS papertape version of he runnable program.
You will only have to keep the helloworld.pas and the resulting program runhelloworld.bin and pap, the others can be made again.
Command Line Utilities
The steps described above for PascalM2k1 can also be done with command line utilities. No argument given will prompt for answers.
Help given with -h. Functionality and steps identical to the PascalM2K1 program. Same files produced.
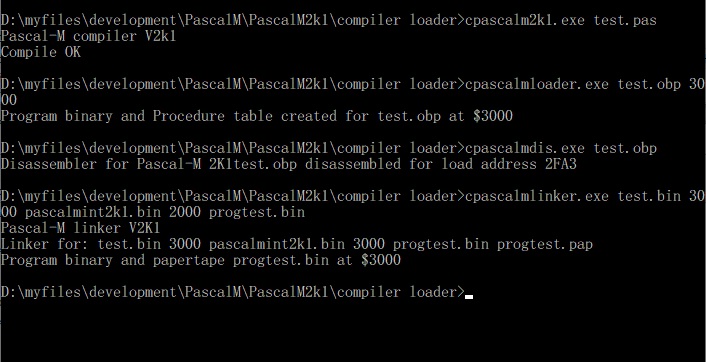
- cpascalm2k1.exe Pascal-M compiler V2k1
Syntax:
cpascalm2k1 <sourcefile> [V]
produces sourcefile.err (status) and sourcefile.obp (object) files
V shows errors on console
- cpascalmload.exe Loader for Pascal-M 2K1
Syntax:
cpascalmload <objectfile>[<loadaddress in hex>]
- cpascalmlinker.exe Pascal-M linker 2K1
Syntax:
cpascalmlinker <binfile from loader> <start adress> <interpreter binary><binary startaddres> <linked program file> <upper memory>
- cpascalmdis.exeDisassembler for Pascal-M 2K1, see the Debug section
Syntax:
cpascalmdis <objectfile> <loadaddress in hex>
Pascal-M limitations
Pascal-M is close to standard Pascal, but there are limits due to the P2 origin (close to the second ‘Pascal User Manual and Report’,
recommended as description for Pascal-M) and the limitations to make a small compiler for an 8 bit target.
When you read the compiler source (pascalmcompiler.inc) you will see it is a real language, and can compile itself
(if you strip all enhancements made by me, see SMPASCAL.PAS on the website for the last version that compiles on the KIM-1!)).
This list sums up the important limitations:
- Identifiers are unique in the first 8 characters
- No reals
- Only text files (7 max)
- 16 bit integers
- max store size 32768 bytes
- set max 63 members
- max 100 procedures/functions, call depth max 12
Memory layout
A Pascal-M program requires RAM from $2000 and up.
The upper limit is variable and can be maximum $DFFF.
The memory layout of a Pascal-M 2K1 system is:
Interpreter start $2000 - $2F00 : Pascal-M 6502 interpreter
$2F00 - $2FFF : procedure buffer
Load address $3000 - + size of M-code
.
.
heap growing up
.
.
stack growing down
- $9FFF = Upper memory
(can be $DFFF for a 48K system)
The interpreter starts at $2000, point the monitor there and Go. After the Jump the memory layout is found: first location of M-code (default $3000), end of memory (default $9FFF) and end of M-code/start of heap (dependent on the size of the M-code).
The linker fills these addresses.
Console interpreter and debugger
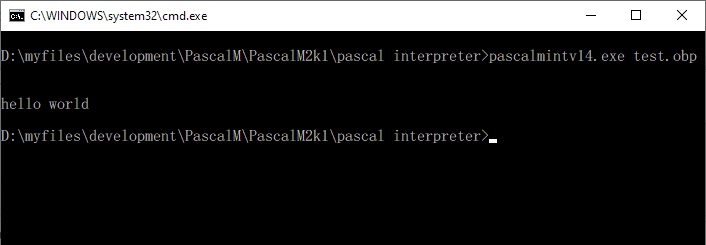
cpascalmint2k1.exe is a command line Mcode interpreter and debugger.
Syntax:
pascalmint2k1 [<name of Mcode object>] [debug]
Without the optional debug parameter the Mcode program is executed:
D:\myfiles\development\PascalM\PascalM2k1\pascal interpreter&amp;gt;pascalmint2k1.exe test.obp
hello world
With the debug parameter a command line drive debugger is started. Use also the Mcode disassembly output to see what is happening in the Mcode machine.
D:\pascalmint2k1.exe test.obp debug
Program ctest Loaded
PC = 7CFC
M-Debug >?
Available debug commands :
B = Breakpoint commands
C = Show stack contents
D = Display store
E = Show stack contents
G = Continue without debugger
H = Show heappointer
I = Insert in store
M = Show markpointer
N = Next instruction executed
P = Show programcounter
S = Show stackpointer
T = Show procedure table
X = Exit interpreter
PC = 7CFC
M-Debug >
Break subcommand >?
Available Break commands :
C = Clear all breakpoints
D = Show all breakpoints
S = Set breakpoint
Compiling and building the programs from source
Prerequisites
- A modern PC and operating system. Windows 10 is where the software has been developed, Raspberry OS /Linux have seen limited tested for now. MacOS may work, untested
- Development (Compile and run everywhere!) with Freepascal and Lazarus IDE (2.x) see https://www.lazarus-ide.org/
Any version above 2.0 will be OK, No OS dependent functions are used a.f.a.i.k.
- The archives with the KIM-1 Simulator sources PascalM2k1sources.zip (or higher version).
- Unpack in a folder, avoid blanks in folder and filenames
- Start the IDE by clicking on the relevant .lpi file.
- Build with Run – Build
The system is made up of main programs that ‘include’ the actual functionality. This way the command line utilities and the GUI pascalM2k1 share the code.
If a change is made to an .inc file both vcalling programs may need attention and tests.
No extra components are used, standard Lazarus will do.
Note that the ‘mode’ of the units is important, the compiler needs mode $delphi.
The 6502 interpreter is living in the folder 6502interpreter.
No special assembler syntax is used, TASM 32 bit for Windows command line is included.
tasm -65 pascalmint2k1.asm -b pascalmint2k1.bin
TASM 6502 Assembler. Version 3.2 September, 2001.
Copyright (C) 2001 Squak Valley Software
tasm: pass 1 complete.
tasm: pass 2 complete.
tasm: Number of errors = 0
will produce the pascalmint2k1.bin file required
Port to other systems
The Pascal-M system is easy to port to other systems. Another 6502 system is quite easy, adaptations on the assembler source will be:
- Character I/O, replace the KIM TTY in/out (note the ‘echo’ adaptation, so no hardware echo on the KIM-1!) with the relevant character I/O routines of the new target
- Take look at the memory layout of the new target, adapt lower and upper memory address in use. It is possible to let the interpreter be independent in memory from the M-code.
The Pascal-m2K1 does not support this, you will have to manage the binary files and memory management in the interpreter yourself
Another platform is a bit more work. Use an assembler or compiler, the interpreter needs to be written for the new target. Take the Pascal interpreter as example, it is well documented.
Introduction and history
How I spent 40 years on getting so far ….
Pascal-M is the name of the Pascal compiler written by Mark Rustad, around 1977.
It was based (and mostly identical) to the portable P2 Pascal compiler, from the ETH Zurich group led by Niklaus Wirth.
The Px Pascal compilers are portable compiler-interpreters, quality compilers and easy to adapt interpreter to new hosts.
The adaptations by Mark Rustad were in the code production, the M-code is byte oriented and more efficient in memory demands.
File I/O was stripped as was floating point. Only chars, integers 16 bit and booleans. Uppercase only. Input/output was for a teletype, so input was either the keyboard or a HSR (High Speed Reader), output a printer or a HSP( High Speed Punch) via a software
switch.
Mark Rustad told me he ported the compiler to 6800 and 6809. G.J. van der Grinten did work on the interpreter part for the KIM-1 and wrote a 6502 interpreter.
The Micro Ade editor was adapted to produce Pascal text files.
In 1978 I received from the KIM Club in the Netherlands a version of this Pascal-M system, consisting of a KIM-1 tape with the compiler and interpreter and Micro Ade,
listings of the compiler (in Pascal), preliminary M-code description, the interpreter (in 6502 assembler) and the Micro Ade patches.
It was never made into a product for the KIM club, it was a nightmare to use. From entering text to running a program, all from audio cassette files, it took around an hour.
The old days of papertape and cards were gone already. But the time of cross-compiling or floppy drives connected to the KIM-1 was not there yet.
I got no further than a ‘Hello world’ program once and gave up.
In 1983 I started typing in the source on a PDP-11 with RSX-11M Pascal. And moved on to VAX/VMS with the excellent VMS Pascal. After some years I had the compiler, an interpreter
written in Pascal with debugger and the original 6502 interpreter on tape. This system produced for the second time, in 1986, a running ‘Hello world’ on the KIM-1.
I started expanding the compiler, bringing back P2 functionality like file handling, text files are now supported. Lowercase also. Bugs fixed.
But then I bought a CP/M system and the KIM-1 was put aside. Pascal-M forgotten for several years, Pascal compiler technology not.
I came back in MS-DOS times to the Pascal-M system with the compiler running as a Turbo Pascal (1994, 2003). Then Delphi arrived and the Pascal-M system was brought to live again as Delphi console applications.
In 2020 this was compiled in Freepascal, the compiler was cleaned up (and the original source restored also).
And now in 2021 a Lazarus shell around the steps required to produce a working program was programmed. The 6502 interpreter was finally assembled from source again.
Pressing a couple of buttons is now all it takes to produce a program running on the KIM-1 (and as console on the PC).
The command line utilities are refreshed also. So a ‘Hello World’ takes a a couple of minutes from source editing to running on the KIM-1 (Simulator).
The motivation for the KIM-1 Simulator was mostly for being able to test the Pascal-M system!
Error messages from the compiler
2 Syntax: identifier expected
3 Syntax: Program expected
4 Syntax: ")" expected
5 Syntax: ":" exepected
6 Syntax: illegal symbol
7 Syntax: actual parameter list
8 Syntax: OF expected
9 Syntax: "(" expected
10 Syntax: type specfication expected
11 Syntax: "[" expected
12 Syntax: "" expected
13 Syntax: end expected
14 Syntax: ";" expected
15 Syntax: integer expected
16 Syntax: "-" expected
17 Syntax: begin expected
18 Syntax: error in declaration part
19 Syntax: error in field list
20 Syntax: "," expected
21 Syntax: "*" expected
50 Syntax: "error in constant
51 Syntax: ":=" expected
52 Syntax: then expected
53 Syntax: until expected
54 Syntax: do expected
55 Syntax: to/downto expected
56 Syntax: if expected
58 Syntax: ill-formed expression
59 Syntax: error in variable
101 Identifier declared twice
102 Low bound exceeds high-bound
103 Identifier is not a type identifier
104 Identifier not declared
105 Sign not allowed
106 Number expected
107 Incompatible subrange types
110 Tag type must be an ordinal type
111 Incompatible with tag type
113 Index type must be an ordinal type
115 Base type must be scalar or subrange
116 Error in type of procedure parameter
117 Unsatisfied forward reference
118 Forward reference type identifier
119 Forward declared : repetition par. list
120 Function result: scalar,subrange,pointer
122 Forward declared: repetition result type
123 Missing result type in function declar.
125 Error in type of standard function par.
126 Number of parameters disagrees with decl
129 Incompatible operands
130 Expression is not of SET type
131 Test on equality allowed only
132 Inclusion not allowed in set comparisons
134 Illegal type of operands
135 Boolean operands required
136 Set element must be scalar or subrange
137 Set element types not compatible
138 Type must be array
139 Index type is not compatible with decl.
140 Type must be record
141 Type must be pointer
142 Illegal parameter substitution
143 Illegal type of loop control variable
144 Illegal type of expression
145 Type conflict
147 Case label and case expression not comp.
148 Subrange bounds must be scalar
149 Index type must not be an integer
150 Assignment to standard function illegal
152 No such field in this record
154 Actual parameter must be a variable
155 Control variable declared interm. level
156 Value already as a label in CASE
157 Too many cases in CASE statement
160 Previous declaration was not forward
161 Again forward declared
169 SET element not in range 0 .. 63
170 String constant must not exceed one line
171 Integer constant exceeds range(32767)
172 Too many nested scopes of identifiers
173 Too many nested procedures/functions
174 Index expression out of bounds
175 Internal compiler error : standard funct
176 Illegal character found
177 Error in type
178 Illegal reference to variable
179 Internal error : wrong size variable
180 Maximum number of files exceeded