The Language PICL and its Implementation, Niklaus Wirth, 20. Sept. 2007
PICL is a small, experimental language for the PIC single-chip microcomputer. The class of computers which PIC represents is characterized by a wordlength of 8, a small set of simple instructions, a small memory of at most 1K cells for data and equally much for the program, and by integrated ports for input and output. They are typically used for small programs for control or data acquisition systems, also called embedded systems. Their programs are mostly permanent and do not change.
All these factors call for programming with utmost economy. The general belief is that therefore programming in a high-level language is out of the question. Engineers wish to be in total control of a program, and therefore shy away from complex languages and compiler generating code that often is unpredictable and/or obscure.
We much sympathize with this reservation and precaution, particularly in view of the overwhelming size and complexity of common languages and their compilers. We therefore decided to investigate, whether or not a language could be designed in such a way that the reservations would be unjustified, and the language would indeed be beneficial for programmers even of tiny systems.
We chose the PIC processor, because it is widely used, features the typical limitations of such single-chip systems, and seems to have been designed without consideration of high-level language application. The experiment therefore appeared as a challenge to both language design and implementation.
The requirements for such a language were that it should be small and regular, structured and not verbose, yet reflecting the characteristics of the underlying processor.
Documents:
A Microcontroller System for Experimentation, description, parts of which are published on this page.
PICL: A Programming Language for the Microcontroller PIC, EBNF
The Language PICL and its Implementation, Code generation.
PICL Scanner, Oberon source
PICL Parser, Code Generator, Oberon source
The Language PICL
The language is concisely defined in a separate report. Here we merely point out its particular characteristics which distinguish it from conventional languages. Like conventional languages, however, it consist of constant, variable, and procedure declarations, followed by statements of various forms. The simplest forms, again like in conventional languages, are the assignment and the procedure call. Assignments consist of a destination variable and an expression. The latter is restricted to be a variable, a constant, or an operator and its operand pair. No concatenation of operations and no parentheses are provided. This is in due consideration of the PIC’s simple facilities and ALU architecture. Examples can be found in the section on code patterns below. Conditional and repetitive statements are given the modern forms suggested by E. W. Dijkstra. They may appear as somewhat cryptic. However, given the small sizes of programs, this seemed to be appropriate.
Conditional statements have the form shown at the left and explained in terms of conventional notation to the right.
[cond -> StatSeq] IF cond THEN Statseq END [cond -> StatSeq0|* StatSeq1 ] IF cond THEN Statseq0 ELSE StatSeq1 END [cond0 -> StatSeq0|cond1 -> StatSeq1] IF cond0 THEN Statseq0 ELSIF cond1 THEN StatSeq1END
Repetitive statements have the form:
{cond -> StatSeq} WHILE cond DO Statseq END
{cond0 -> StatSeq0|cond1 -> StatSeq1} WHILE cond0 DO Statseq0 ELSIF cond1 DO StatSeq1END
There is also the special case mirroring a restricted form of for statement. Details will be
explained in the section on code patterns below.
{| ident, xpression -> StatSeq}
The PICL Compiler
The compiler consists of two modules, the scanner, and the parser and code generator. The scanner recognizes symbols in the source text. The parser uses the straight-forward method of syntax analysis by recursive descent. It maintains a linear list of declared identifiers for constants, variables, and procedures.
Example
MODULE RepeatStat; INT x, y; BEGIN REPEAT x := x + 10; y := y - 1 UNTIL y = 0; REPEAT DEC y UNTIL y = 0 END RepeatStat. 0 0000300A MOVLW 10 1 0000078C ADDWF 1 12 x := x + 10 2 00003001 MOVLW 1 3 0000028D SUBWF 1 13 4 0000080D MOVFW 0 13 y := y - 1 5 00001D03 BTFSS 2 3 = 0 ? 6 00002800 GOTO 0 7 00000B8D DECFSZ 1 13 y := y – 1; = 0? 8 00002807 GOTO 7
Example
The following procedures serve for sending and receiving a byte. Transmission occurs over a 3-wire connection, using the conventional hand-shake protocol. Port A.3 is an output. It serves for signaling a request to receive a bit. Port B.6 is an input and serves for transmittithe data. B.7 is usually in the receiving mode and switched to output only when a byte is to be sent. In the idle state, both request and acknowledge signals are high (1).
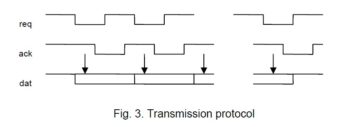
PROCEDURE Send(INT x);
INT n;
BEGIN ?B.6; wait for ack = 1
!S.5; !~B.7; !~S.5; n := 8; switch B.7 to output
REPEAT
IFx.0 -> !B.7 ELSE !~B.7 END; apply data
!~A.3; issue request
?~B.6; wait for ack
!A.3; ROR x; reset req, shift data
?B.6; DEC n wait for ack reset
UNTIL n = 0;
!S.5; !B.7;!~S.5 reset B.7 to input
END Send;
PROCEDURE Receive;
INT n;
BEGIN d := 0; n := 8; result to global vaiable d
REPEAT
?~B.6; ROR d; wait for req
IF B.7 THEN !d.7 ELSE !~d.7 END ; sense data
!~A.3; issue ack
?B.6; wait for req reset
!A.3; DEC n reset ack
UNTIL n = 0
END Receive;
Another version of the same procedures also uses three lines. But it is asymmetric: There is a master and a slave. The clock is always delivered by the master on B.6 independent of the direction of the data transmission on A3 and B7.
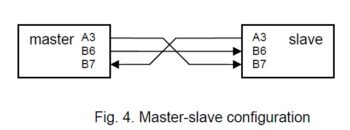
When sending, the data is applied to A.3, when receiving, the data is on B.7. The advantage of this scheme is that no line ever switches its direction, the disadvantage is its dependence on the relative speeds of the two partners. The clock must be sufficiently slow so that the slave may follow. There is no acknowledgement.
Master Slave
PROCEDURE Send(INT x); PROCEDURE Receive;
INT n; INT n;
BEGIN n := 8; BEGIN d := 0; n := 8; result to global vaiable d
REPEAT REPEAT ?~B.6; !>d; wait for clock low
IF x.0 THEN !A.3 ELSE !~A.3 END; IF B.7 THEN !d.7 ELSE ~d.7 END; sense data
!~B.6; !>x; !B.6; DEC n ?B.6; DEC n wait for clock high
UNTIL n = 0 UNTIL n = 0
END Send; END Receive;
PROCEDURE Receive; PROCEDURE Send(INT x);
INT n; INT n;
BEGIN d := 0; n := 8; BEGIN n := 8;
REPEAT !~B.6; ROR d; REPEAT ?~B.6; wait for clock low
IF B.7 THEN !d.7 ELSE ~d.7 END; IF x.0 THEN !A.3 ELSE !~A.3 END; apply data
!B.6; DEC n ROR x ?B.6; DEC n wait for clock high
UNTIL n = 0 UNTIL n = 0
END Receive; END Send;
Conclusions
The motivation behind this experiment in language design and implementation had been thequestion: Are high-level languages truly inappropriate for very small computers? The answer is: Not really, if the language is designed in consideration of the stringent limitations. I justify my answer out of the experience made in using the language for some small sample programs. The corresponding assembler code is rather long, and it is not readily understandable. Convincing oneself of its correctness is rather tedious (and itself error-prone). In the new notation, it is not easy either, but definitely easier due to the structure of the text.
In order to let the regularity of this notation stand out as its main characteristic, completeness was sacrificed, that is, a few of the PIC’s facilities were left out. For example, indirect addressing, or adding multiple-byte values (adding with carry). Corresponding constructs can easily be added.
One might complain that this notation is rather cryptic too, almost like assembler code. However, the command (!) and query (?) facilities are compact and useful, not just cryptic. Programs for computers with 64 bytes of data and 2K of program storage are inherently short; their descriptions should therefore not be longwinded. After my initial doubts, the new notation appears as a definite improvement over conventional assembler code.
The compiler was written in the language Oberon. It consists of a scanner and a parser module of 2 and 4 pages of source code respectively (including the routines for loading and verifying the generated code into the PIC’s ROM). The parser uses the time-honored principle of top-down, recursive descent. Parsing and code generation occur in a single pass.
