Pascal Implementation by Steven Pemberton and Martin Daniels
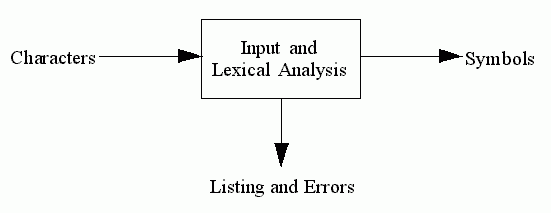
This group of routines is responsible for reading the input, producing a listing, reporting errors, and splitting the input stream into distinct 'symbols' to be passed on to the next stage of the compiler.
Pictorially:
All input in the compiler is done by this procedure. Its purpose is to deliver the next character of the input in variable ch, dealing with the listing, and the end of line and end of file events. The following non-local variables are affected:
The variable eol is used to delay processing of the end of line until all processing of the line itself has been completed, mainly to ensure that all error messages relating to the last item on the line appear with that line.
When eoln(input) is true, the next read(input,ch) will read a space into ch, as required by Pascal. A space terminates all lexical items, except strings, where eol is tested explicitly [486]. Thus the end of line terminates all items.
Whenever the compiler reports an error, this procedure is called with an integer parameter representing the error number. The procedure saves a maximum of 10 errors in a buffer errlist, each element consisting of the error number (ferrnr) and the position at which it occurred (chcnt). Errinx (error index) counts the number of errors reported about the current line; if this number ever exceeds 9, then error 255 -- further errors suppressed -- is saved, and no others are saved for this line. Procedure endofline prints these saved error messages.
This procedure processes end of line: listing errors for the current line, incrementing the line count, printing the two numbers that precede each line of the listing, and resetting chcnt.
write(output, currnmr: 1)
would have the required effect, taking as much space as necessary to print currnmr.
This routine deals with 'pragmatic comments' like the one on line [1]. The format of the options is supposed to be a number of single options separated by commas, each option consisting of a letter followed by a sign. No contained spaces are allowed, and the four options possible are:
The defaults for these are t-, l+, d+, c-, set at line [3800] in procedure initscalars.
Observe that '+' turns any option on, any other character turns it off. You might prefer the following:
if ch = '+' then prcode:=true else if ch = '-' then prcode:=false
Any divergence from the required format causes the rest of the comment to be ignored. Unfortunately, unrecognised options are treated differently to recognised ones. Consider how the following would be treated:
(*$l+,g-,c+*) (*$l+,g,c+*) (*$l,,g,c+*)
You might also like to consider the effect of
(*$l+,c+,d*)
and of
(*$l+,c+,g*)
and indeed of
(*$l+,c+, *)
and consider how to prevent the problems these cause.
This procedure is the heart of the lexical analyser. Its purpose is to skip spaces and comments (interpreting pragmatic comments on the way) and to collect the basic symbols of the program for use by the next phase of the compiler.
The different sorts of symbols are defined by the type symbol, [80-86], and may be split into several classes:
A symbol is represented by the following group of global variables:
The routine works by getting the next character, deciding on the basis of this which sort of token it is going to be, and then collecting characters as long as they can be part of that sort of token.
The routine may be split into several distinct parts:
These 4 lines of code deal with unknown characters, reporting error 399, and setting sy to othersy, which is a symbol not recognised by the syntax analyser.
The array chartp is an array that defines the 'character type' of each character in the available character set.
You will find chartp declared [284] as
array [char] of chtp
where chtp is defined as [90-91]
(letter, number, special, illegal, chstrquo, chcolon, chperiod, chlt, chgt, chlparen, chspace)
You will find chartp initialised in procedure chartypes, [3908-44]: here all elements are filled with illegal before filling in elements that are known, thus leaving illegal in unknown elements.
The P4 compiler attempts as far as possible to be portable between different machines, and therefore tries to assume as little as possible about the character set available. The character types beginning 'ch' (chstrquo, chcolon, etc.) are all later additions attempting to increase this character independence, since they require fewer explicit character literals.
Unfortunately, these additions have not been applied uniformly: for example, the character set might include a second 'space' character such as 'tab', so it would be better to skip spaces with
while (chartp[ch] = chspace) and not eol do nextch
rather than the present
while (ch=' ') and not eol do nextch
This goes for most other character literals in the lexical scanner.
The section of code to skip spaces and newlines, [398-401], is so complicated that it deserves a rewrite; furthermore, test is a very poor choice of identifier name, since it reveals little about its use (this may have been a later addition to fix a bug). If its name is changed to fileended, and the assignment fileended:=false is retained in nextch, verify that this section can be replaced by the following code:
while (ch =' ') and not fileended do nextch.
Remember that when eol is true, ch = ' '.
The if statement, [402-6], is quite unnecessary. Far better to include illegal in the case statement that follows it:
case chartp[ch] of
illegal: begin
sy:=othersy
op:=noop
error(399);
nextch
end;
letter: ...
The kind of symbol that is going to be analysed depends on its initial character, so the character type is selected using a case:
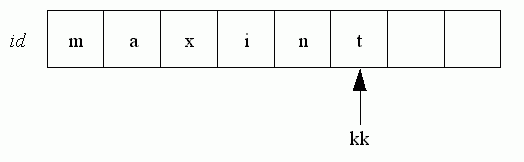
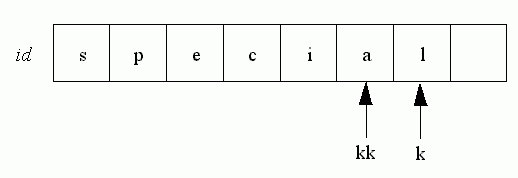
Pad out the rest of id with spaces, k is the length of this identifier, kk the length of the previous identifier. If k is greater than kk, then the rest of id already contains spaces, and kk can be set to k. Otherwise, the remaining characters of id that are not spaces, (those from k to kk) must be made so.
For instance, if the last identifier was maxint, there is the following situation:
If the next identifier is special, it becomes:
Whereas if the following identifier had been char, it would have been
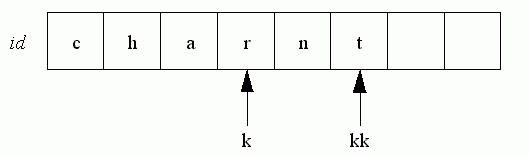
leaving the final nt of maxint to be made into spaces.
Determine if the identifier is a reserved word or not. The reserved words are stored, in ascending length order, in the array rw (reserved words) declared [285], initialised in procedure reswords [3824].
The array frw (first reserved word) is set up so that frw[n] points to the first reserved word of length n in rw, for n = 1 to 8.
Then the search for a particular identifier in the reserved words list may be restricted to the reserved words of the length of that identifier, i.e. frw[k] to frw[k+1] - 1.
If the reserved word is found, the arrays rsy (reserved symbol) and rop (reserved operator) are used to deliver the kind of symbol and the kind of operator that it is.
Pictorially:
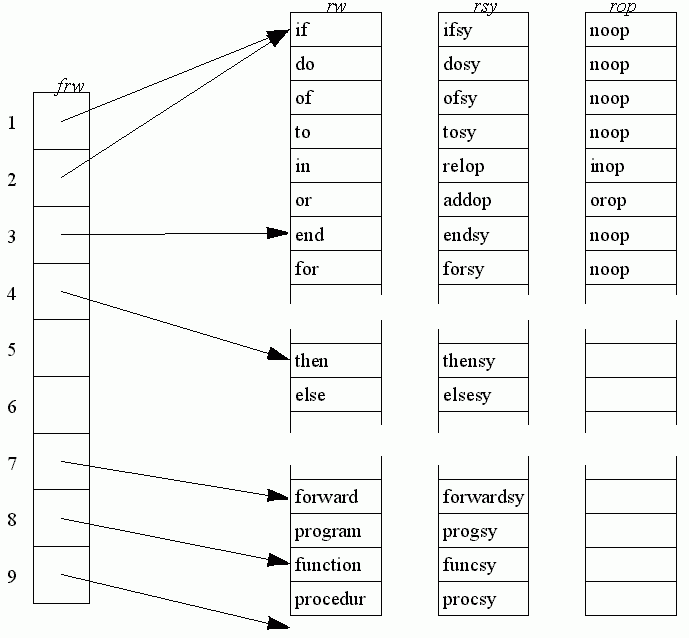
[423] If the word is not a reserved word, then it is just an identifier.
The test, [414-5]
until chartp[ch] in [special, illegal, chstrquo, chcolon, chperiod, chlt, chgt, chlparen, chspace]
is shorter and more obvious if written as the equivalent
until not (chartp[ch] in [letter, number]).
[416-9] It is doubtful whether the optimisations involved in this bit of code are really worth it. They certainly obscure its workings. The clearest alternative would be
for i:=k+1 to 8 do id[i]:=' ';
although there would now be no use for the separate k and kk, and the kk:=k could be eliminated.
Less obvious, but retaining most of the optimisation would be
for i:=k+i to kk do id[i]:=' '; kk:=k
but the simpler first alternative seems preferable, since it depends less on its surroundings. The optimisations applied here really seem to gain only a microscopic amount of efficiency, and should be avoided.
The overview of this section is:
Before examining this section in detail, it is first necessary to study how constants are stored.
The values of integer, real, character, and string literals produced by the lexical analyser are stored in global variable val of type valu.
Valu is declared, [105-8], as a variant record:
valu = record case intval: boolean of
true: (ival: integer)
false: (valp: csp)
end;
where field ival is for storing integer and character literals holding the integer value or the ordinal value of the character, and field valp for all other types of literal.
The comment 'intval never set nor tested' [105] reflects the fact that the compiler knows from context when it has an integer or character literal and when it does not.
The field valp is of type csp, (constant pointer), where csp is constant and constant is a further variant record with three variants, (reel, strg, and pset), one for reals, one for strings, and one for set literals. (Set literals are not constructed by the lexical analyser, but by the syntax analyser, line [2830] onwards). Sets are held as a set of (small) integers, strings as a short string (up to a maximum of strglgth characters) with an index giving its length, and reals as the string of characters making up the number. Reals are held in this way, so that the compiler itself does not have to do any real arithmetic, which makes it easier to implement initially.
So integers and characters are held
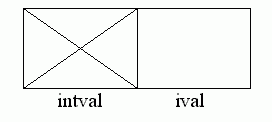
reals, strings, sets
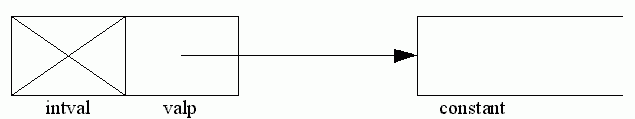
Now to return to the commentary.
Here the real constant is saved.
Lvp is a ^constant; its cclass is set to reel, and the digits of the number are transferred from digit to rval, after initialising rval to all spaces.
Calculates the value of the integer, making sure that it is not too big.
Ordint is an array [char] of integer, only used for the characters '0' to '9' holding the value of each of these digits, i.e. 0 to 9; initialised at lines [3940-3].
Type valu is split into two (one record for integers and characters, one for all others) as a space saving optimisation. Ideally, it would be defined as
cstclass = (int, reel, pset, strg, chrctr);
value = record case cclass: cstclass of
int: (ival integer);
reel: (rval: packed array [1..strglgth] of char)
pset: (pval: set of setlow..sethigh)
chrctr: (cval: char)
strg: (slgth:0..strglgth
sval: packed array [1..strglgth] of char)
end;
However, this would mean that every object of type valu would need to be large enough to accommodate the largest of these variants (probably strg). Obviously, the designers of the compiler anticipated more integer and character literals than other kinds and so treated them specially to save space. Thus reals, strings and sets need space for one extra pointer -- valp (and of course, extra time to access via valp) -- but integers and characters need very much less space.
An additional space saving advantage is that a constant can be created using new with the necessary size, for example, new(lvp, reel) [454].
The treatment of the 1..10 case [434] is verging on the abominable. The jump from the then part of an if statement into its else part is probably the worst bit of programming in the compiler. It is unlikely that Pascal even allows it, and many Pascal compilers refuse it. In this edition we have rewritten it without a goto, leaving the original code as a comment.
rval[1] is left blank [458] to allow for an optional sign which may get filled by the syntax analyser, should this number be part of a constant declaration such as
const z =-3.14
(several places in procedure constant, starting line [864]).
The test if ival <= mxint10 [473] is meant to ensure overflow does not occur in the next line when ival is multiplied by ten. Mxint10 is initialised [3808] to the value maxint div 10.
However, the test is not correct: for example if maxint = 1000, ival = 100, and k = '1'. It is necessary to ensure that the new value of ival will not cause overflow, i.e. that
ival * 10 + ordint[digit[k]] <= maxint
that is,
ival * 10 <= maxint - ordint[digit[k]]
that is,
ival <= (maxint - ordint[digit[k]]) div 10.
This is the test wanted, and mxint10 can be eliminated in the process.
Pascal guarantees that the characters '0' to '9' are all in one group in the character set. Therefore the declaration of ordint [296]
ordint: array[char] of integer
could better be declared as
ordint: array['0'.. '9'] of 0..9
as this exactly reflects its use. However, because of Pascal's guarantee, the value of a digit character can be calculated using the expression
ord(ch) - ord('0').
Therefore, line [474] which reads
ival:=ival - 10 + ordint[digit[k]]
may be changed to
ival: = ival * 10 + (ord(digit[k]) - ord ('0'))
(the brackets are essential to avoid causing overflow in critical cases). With this change, ordint may be eliminated entirely.
Collect the characters of the strings. If the string extends over a line, error 202 results.
The outer loop deals with quotes within strings, which are represented as two single quotes, e.g. '''': the inner loop terminates when a single quote is met, and this quote is saved. The outer loop then continues if a further quote follows, but this quote is not saved. If a second quote does not follow, then the double loop terminates.
That strings can only be a maximum of strglgth characters long is one of the more inconvenient restrictions of this compiler. One of the many possible solutions would be to store strings as a list of pieces, for instance:
type constant = record case cclass: cstclass of strg: (slth: integer; sval: piece) end; piece = record chars: array [1..piecemax] of char; nextpiece: ^piece end;
As before with spaces, the termination tests would best be
(chart[ch] = chstrquo).
This deals with all single character symbols and operators not already dealt with: + - * / ) = , [ ] ^ ; .
Ssy yields the kind of symbol, sop the kind of operator if it is one, noop otherwise.
Since when dealing with integers directly followed by '..', ch gets set to ':' [434], '..' sometimes gets treated as a colon. Consider why then, '..=' never gets accepted as a substitute for ':='.
Does
type index=0:9
ever get accepted? How about for labels?
1..a:=0
Label 1 is really just a loop
while commentskipped do
or
repeat... until symbolfound.
Consider the changes necessary.
Another solution would be to replace the goto 1 by a (recursive) call to insymbol.
Throughout the compiler there are several groups of variables that really form single units. Such groups are for example
ch + chcnt, a character and its position.
errlist + errinx, the error list and its index
For documentation reasons, it would seem quite a good idea to physically group these together as records, for example:
var ch: record val: char; pos: integer end;
error: record numbers: array[1..10] of record pos: integer; nmr: 1..400 end; index: 0..10 end; options: record list, debug, check, printtables: boolean end;
and access them
if option.list then
while ch.val=' ' do ....
While about it, another field could be added to the ch record: class: chtp and ch could always be updated with its type. Then the following could be written:
while (ch.class = chspace) and not fileended do nextch
Throughout the lexical analyser, there seems to be a tacit assumption that eoln will directly precede eof. For example [484]
repeat nextch until (eol) or (ch='''')
Pascal does not require this to be true. One solution would be in nextch to write
if eof(input) then begin writeln(output, '*** eof', 'encountered') ch.class := illegal; ch.val := ' '; fileended := true end else
Then, most symbols would terminate with the illegal character class, and those that would not (strings and comments) could explicitly test:
repeat nextch; ... until eol or fileended or (ch.class = chstrquo)
Another solution would be to completely revise the treatment of file events. If, instead of the two variables eol and fileended there was a single variable:
var filestate: (normal, lineended, fileended)
firstly this would more clearly show that eol and fileended will never occur simultaneously; but more importantly it simplifies a great many tests, for now may be written
while (filestate = normal) and (ch.class = digit) do ...
and
repeat nextch; .... until (filestate <> normal) or (ch.class = chstrquo)
to include both eoln and eof.
Throughout the compiler, there are procedures that are really too long. Here, insymbol provides a good example: its final end is some 300 lines away from its heading, and this makes for quite difficult reading.
It seems a good idea to split such large routines up. For example, insymbol into procedures skipspaces, inidentifier, innumber, instring, etc.
Then the body of insymbol could be:
skipspaces; case ch.class of letter: inidentifier; number: innumber; chstrquo: instring; ....
Similar reasoning could be made for a procedure skipcomment to replace [533-40].
It could be argued that such routines, called from only one place, are a bad idea on the grounds of efficiency. However the increased readability easily compensates for the slight decrease in efficiency. Besides, there are several precedents: for example endofline.
Similarly throughout the compiler there are several pieces of very repetitious code that ideally should be put in one place as a single routine.
Examples are at lines [427, 433, 437, 442, 445, 450] where there is something like
k:= k+1; if k <= digmax then digit[k] := ch; nextch.
It would be better to make this sequence into a procedure, say savedigit, and write
repeat savedigit until ch.class <> number
which is very much more readable. (Adopting this, [431] would need to be changed to i := k.)
At lines [378...] there could be a procedure
procedure setoption(var option: boolean); begin if ch.val <> '*' then nextch; if ch.val = '+' then option := true else if ch.val = '-' then option := false end;
Then in procedure options:
if ch = 't' then setoption(prtables) else if ch = 'l' then setoption(list) etc.
There is a problem with the parameterisation of the target machine [34-56]. The identifiers maxint, ordminchar, and ordmaxchar are used here to specify properties of the target machine, but this is a mistake since these three identifiers are used as a standard to mean values of the machine that the program is running on.
This probably reflects an original assumption that the compiler would run on the same machine that it was generating code for. However, this is not necessarily the case, and to partly solve the problem there should really be three other values, say intmax, charmin, and charmax to represent the target machine's properties, and then be very careful about which was used where.
An example of such a use is in the initialisation of the array chartp on line [3911] - Here it is the source machine's character set, i.e. ordminchar and ordmaxchar as such that is meant. Later it will be seen that the use of ordminchar and ordmaxchar on line [639] the target machine's characters are meant.
A larger, more pervasive problem with the differences between the source and target machine is if the target machine has a value of maxint larger than the source machine can handle. Since the values of integer literals are calculated within the compiler, only major surgery could solve this.
A similar problem occurs with sets if the source machine has smaller sets than the target machine. A solution to this would be to hold pval of type constant as an ordered list of integers.
However, possibly the worst problem in the mismatch between source and target machines is that for accesses to arrays whose index types are character, and for case statements on characters, wrong code is generated for machines whose character set is different to the source machine's. This is discussed in the relevant sections.
Pascal Implementation by Steven Pemberton and Martin Daniels
Copyright © 1982, 2002 Steven Pemberton and Martin Daniels, all rights reserved.