Alle bisher behandelten Daten (-typen) besitzen eine fest definierte konstante Größe. Ein Vorteil von Variablen dieser Typen ist, daß sie jederzeit im Programm direkt über ihren Namen (evtl. gefolgt von einem Index in eckigen Klammern oder einem Feldnamen nach einem Punkt) angesprochen werden können. In der Definition der Sprache Pascal wird jedoch auch eine Datenstruktur angegeben, deren Größe während der Laufzeit eines Programmes variabel ist. Dafür ist der Zugriff auf Elemente der Sruktur nur in fester Reihenfolge mit speziellen Prozeduren möglich. Diese Struktur heißt File und formalisiert das Konzept der sequentiellen Dateien.
Zu jedem Typ T läßt sich mit FILE OF T ein File mit dem Komponententyp T bilden. Beispiele für Deklarationen von Filevariablen sind in Bild 73 gegeben. Dabei werden Typbezeichner benutzt, die bereits in Bild 65 und 69 definiert wurden. ADRESSBUCH ist also eine Filevariable mit Komponenten vom Typ ADRESSE.
TYPE (* siehe Bild 65 und Bild 69 *)
VAR ZAHLENSPEICHER = FILE OF INTEGER;
KOEFFIZIENTEN = FILE OF REAL;
TEXTFILE = FILE OF CHAR;
BILDDATEI = FILE OF TOBJEKT;
ADRESSBUCH = FILE OF ADRESSE;
Bild 73: Deklaration von Filevariablen
Das englische Wort file bezeichnet ursprünglich einen Ordner oder eine Sammelmappe. In der Datenverarbeitung wird file am besten mit Datei übersetzt. Dateien sind Folgen (gleichartiger) Daten, die meist auf externen Massenspeichern abgelegt werden. Da die Verwaltung von Dateien auf verschiedenen Computern sehr unterschiedlich realisiert wird, beschränkt sich Pascal auf elementare Operationen mit sequentiellen Dateien. Dennoch weichen viele Implementierungen der Sprache vom nachfolgend (und im report) beschriebenen Standard ab.
VAR F: FILE OF T;
deklariert eine Filevariable F. Diese Variable besteht aus einer (eventuell leeren) Folge von Komponenten des Typs T. Somit besteht die Variable BILDDATEI aus einer Folge von Records des Typs TOBJEKT. Die Anzahl der Komponenten innerhalb eines Files ist veränderlich. Der Zugriff auf die Komponenten kann nur sequentiell lesend oder sequentiell schreibend erfolgen. Zu jedem Zeitpunkt während der Programmausführung ist nur eine Komponente von F sichtbar. Sie wird mit F^ wie eine »normale« Variable in Zuweisungen und Ausdrücken bezeichnet. F^ wird auch die Puffervariable des Files F genannt.
2.16.1 Sequentiell schreiben
Mit dem Prozeduraufruf REWRITE(F) wird F zum Schreiben vorbereitet. Alle Komponenten der Variablen F werden gelöscht. Nun kann man der Puffervariablen F^ einen Wert vom Typ T zuweisen. Durch den Prozeduraufruf PUT(F) wird der Inhalt der Puffervariablen als eine neue Komponente in F aufgenommen. Jeder Aufruf PUT(F) erweitert F um eine Komponente. Die Komponenten werden in der Reihenfolge gespeichert, in der sie mit PUT erzeugt wurden.
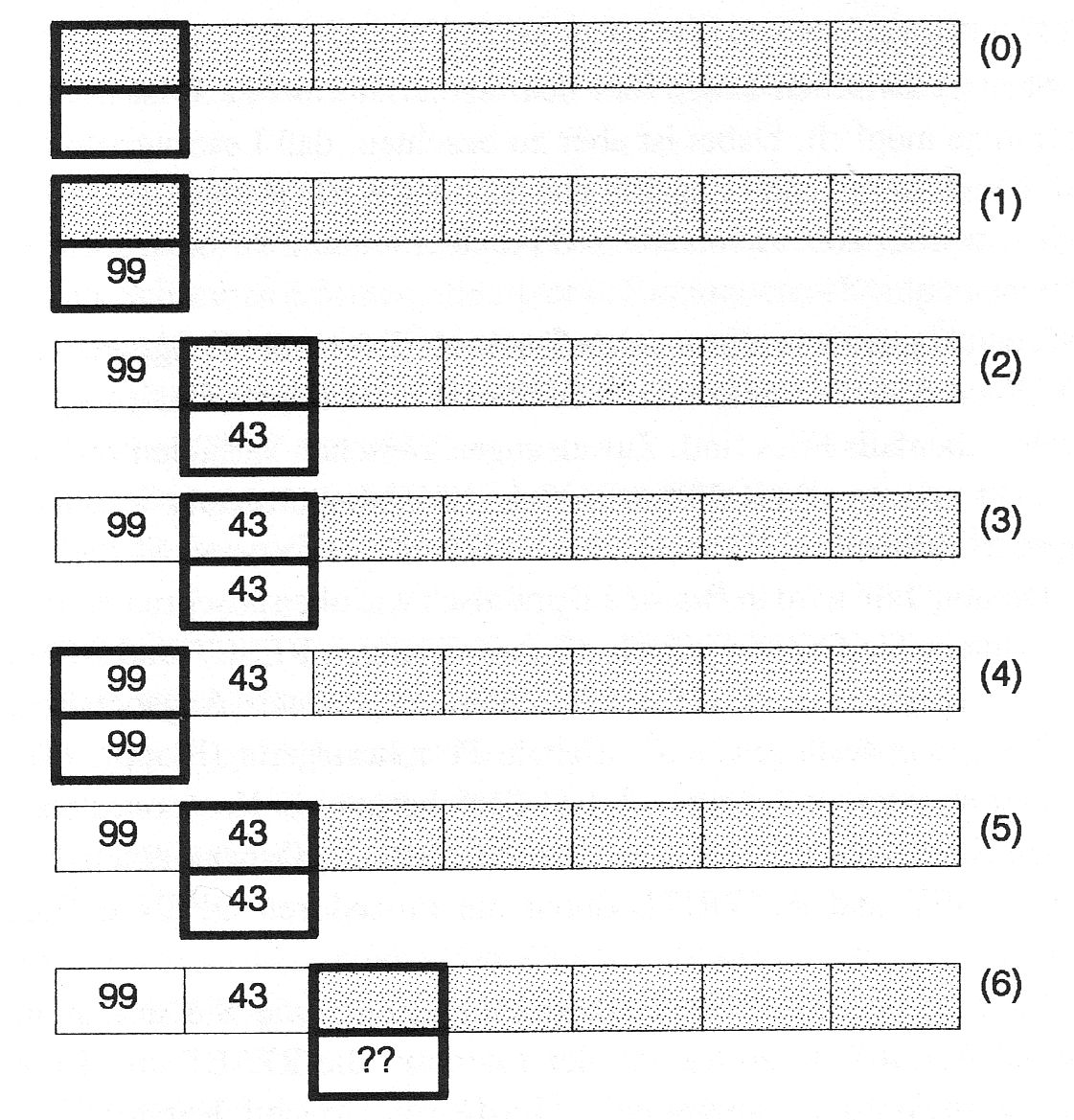
Diese abstrakten Regeln soll ein kleines Programmstück und Bild 75 erläutern. Es werden nacheinander zwei Zahlen (99 und 43) auf das File D gespeichert. Da die Datei D ganze Zahlen speichern soll, wird sie mit dem Typ FILE OF INTEGER deklariert. Nachdem das File zum Schreiben eröffnet wurde, ist das File leer und der Inhalt der Puffervariablen D^ undefiniert (Bild 75.0). Nun werden die zu schreibenden Zahlen zunächst der Puffervariablen zugewiesen, und dann mit PUT(D) der Inhalt von D^ auf das File geschrieben. Damit ergibt sich der in Bild 75.1-3 dargestellte Inhalt von D. Dabei wird die Puffervariable als »Fenster« in das File dargestellt.
PROGRAM WRITEFILE (INPUT,OUTPUT) (* Dieses Programm muß in PASCAL 2.0 umformuliert werden! *) (* s. Text! *) VAR D: FILE OF INTEGER; BEGIN REWRITE(D); (* --- 0 --- *) D^:= 99; (* --- 1 --- *) PUT(D); D^:= 43; (* --- 2 --- *) PUT(D); (* --- 3 --- *) END.
Bild 74: File schreiben
Bild 75: Darstellung der Dateiopeationen
2.16.2 Sequentiell lesen
Um die in einer Filevariablen gespeicherten Daten wieder zu lesen, muß man zunächst F mit dem Prozeduraufruf RESET(F) zum lesenden Zugriff vorbereiten. Dabei wird der Puffervariablen F^ die erste Komponente in F als Wert zugewiesen. Dieser Wert kann nun beliebig in Ausdrücken verwendet werden. Durch den Aufruf von GET(F) wird der Wert der nächsten Komponente von F nach F^ übertragen. Somit kann man durch eine Folge von Aufrufen der Prozedur GET jede Komponente in F erreichen. Die Funktion EOF(F) (engl. end of file, Dateiende) liefert den Wert TRUE, falls beim sequentiellen Lesen das Ende des Files F erreicht wurde. Dann ist der Inhalt der Puffervariablen F^ undefiniert. Beim Schreiben mit REWRITE und PUT ist EOF(F) immer TRUE.
Ein kleines Programmstück und Bild 75 zeigen das Lesen der im Abschnitt 2.16.1 erstellten sequentiellen Datei D.
PROGRAM READFILE (INPUT,OUTPUT);
(* Dieses Programm muß in PASCAL 2.0 umformuliert werden! *)
(* s. Text! *)
VAR D: FILE OF INTEGER;
BEGIN
RESET(D); (* --- 4 --- *)
WRITE(D^);
GET(D); (* --- 5 --- *)
WRITE(D^);
GET(D); (* --- 6 --- *)
IF EOF(D) THEN
WRITELN('Dateiende erreicht!');
END.
Bild 76: File lesen
Ein Wechsel zwischen Lesen und Schreiben auf ein File F ist in beliebiger Reihenfolge möglich. Dabei ist aber zu beachten, daß Lesezugriffe nur nach RESET und schreibende Zugriffe nur nach REWRITE möglich sind. Außerdem löscht jeder Aufruf von REWRITE alle eventuell zuvor in F enthaltenen Komponenten!
Filetypen können wie alle anderen Typen als Teil zusammengesetzter Datentypen (Record, Array) auftreten. Jedoch sind keine Files zulässig, deren Komponenten ebenfalls Files sind. Zuweisungen zwischen Variablen vom Typ File sind nicht erlaubt. Files dürfen nur als Variablenparameter an Prozeduren übergeben werden.
Der Datentyp File wird in Pascal 2.0 praktisch wie oben beschrieben realisert. Einen Unterschied bilden jedoch die Anweisungen RESET und REWRITE. Das Betriebssystem des C-128 erwartet nämlich genauere Angaben über jedes File. Man muß festlegen, auf welchem Peripheriegerät (Floppy, Datasette, Festplatte an externer Schnittstelle) die Speicherung der Komponenten erfolgt, welchen Namen das File auf dem Medium erhält etc. Daher werden die Prozeduren RESET und REWRITE durch die Prozeduren OPEN und CLOSE ersetzt.
An dieser Stelle wird eine Methode vorgestellt, wie Sie mit minimalem Aufwand Pascalprogramme aus der Literatur, die RESET und REWRITE benutzen, in Pascal 2.0 umwandeln. Um die volle Mächtigkeit der Prozeduren OPEN und CLOSE zu nutzen, finden Sie aber in Kapitel 3 und der Dokumentation in Kapitel 4 genauere Hinweise zu diesen Standardprozeduren.
In Pascal 2.0 wird eine Datei mit dem Prozeduraufruf
OPEN(Filevariable, 8, 3, 'DATEN,SEQ,WRITE')
zum Schreiben eröffnet. Damit werden alle Daten der Filevariablen in der sequentiellen Datei mit dem Namen »DATEN« auf der Diskette gespeichert. Die Zahl 3 bildet eine sogenannte Sekundäradresse. Haben Sie mehrere Filevariablen in Ihrem Programm, so muß jede eine eigene Sekundäradresse (3, 4, 5, 6 bis 14) und einen eigenen Filenamen (»DATEN1«, »DATEN2« etc.) erhalten. Anschließend können Sie die Daten wie oben beschrieben mit PUT(Filevariable) ausgeben. Am Ende der Ausgabe muß außerdem die Datei geschlossen werden:
CLOSE(Filevariable)
Um eine Datei zum Lesen zu eröffnen, verwenden Sie ebenfalls die Prozedur OPEN. Wählen Sie dabei denselben Filenamen wie beim Schreiben. Die Sekundäradresse muß wiederum eindeutig aus dem Intervall 3 bis 14 gewählt werden:
OPEN(Filevariable, 8, 3, 'DATEN,SEQ,READ')
Nach diesem OPEN-Befehl ist der Inhalt der Puffervariablen noch undefiniert. Mit GET(Filevariable) können Sie die Datei wie oben beschrieben komponentenweise lesen. Auch nach dem Lesen muß eine Datei wieder geschlossen werden:
CLOSE(Filevariable)
Bitte beachten Sie, daß bei aufeinanderfolgenden OPEN-Befehlen, die eine Datei F zum Schreiben eröffnen, die zuvor in F enthaltenen Komponenten nicht automatisch gelöscht werden. Sie müssen daher zuvor einen expliziten Löschbefehl angeben. Dies geschieht ebenfalls mit einer Filevariablen:
VAR COMMAND : FILE OF CHAR; OPEN(COMMAND,8,15,'S0:DATEN'); CLOSE(COMMAND);
Damit sehen die Beispielprogramme aus Bild 74 und 76 in Pascal 2.0 folgendermaßen aus:
PROGRAM WRITEREADFILE (INPUT,OUTPUT);
(* So sehen Bild 74 und 76 in PASCAL 2.0 aus *)
VAR D : FILE OF INTEGER;
COMMAND: FILE OF CHAR;
BEGIN
(* Zuerst evtl. vorhandene Daten löschen: *)
OPEN(COMMAND,8,15,'S0:DATA'); CLOSE(COMMAND);
OPEN(D,8,3,'DATA,SEQ,WRITE'); (* --- 0 --- *)
D^:= 99; (* --- 1 --- *)
PUT(D); D^:= 43; (* --- 2 --- *)
PUT(D); (* --- 3 --- *)
CLOSE(D);
OPEN(D,8,3,'DATA,SEQ,READ');
GET(D) (* --- 4 --- *)
WRITE(D^);
GET(D); (* --- 5 --- *)
WRITE(D^);
GET(D); (* --- 6 --- *)
IF EOF(D) THEN
WRITELN('Dateiende erreicht!');
CLOSE(D);
END.
Bild 77: Fileoperationen in Pascal 2.0
Da die Länge eines Files variabel ist, verwendet man bei der E Ein- und Ausgabe sinnvollerweise While- und Repeat-Anweisungen. Das generelle Schema für die Ein- und Ausgabe sequentieller Dateien zeigt Bild 78. Dort werden die Quadratwurzeln der ersten 100 ganzen Zahlen in der Filevariablen SQUAREROOT gespeichert und nachfolgend gelesen.
PROGRAM ROOTS (INPUT,OUTPUT);
VAR SQUAREROOT: FILE OF REAL;
COMMAND : FILE OF CHAR;
I : INTEGER;
BEGIN
OPEN(COMMAND,8,15,'S0:SQRT'); CLOSE(COMMAND);
OPEN(SQUAREROOT,8,3,'SQRT,SEQ,WRITE');
FOR I:= 1 TO 100 DO
BEGIN
SQUAREROOT^:= SQRT(I); PUT(SQUAREROOT);
END;
CLOSE(SQUAREROOT);
OPEN(SQUAREROOT,8,3,'SQRT,SEQ,READ');
GET(SQUAREROOT);
WHILE NOT EOF(SQUAREROOT) DO
BEGIN
WRITELN(SQUAREROOT^ :15:7); GET(SQUAREROOT);
END;
CLOSE(SQUAREROOT);
END.
Bild 78: Ein File mit reellen Komponenten
Wie für Arrays existieren auch für Files zahlreiche verschiedene Sortierverfahren, die jeweils für spezielle Anwendungsgebiete optimale Ergebnisse liefern. Bei der Sortierung eines Files muß jedoch erschwerend die Tatsache berücksichtigt werden, daß die Daten nur in einer festen Reihenfolge nacheinander zur Verfügung stehen. Natürlich kann man ein File sequentiell in ein Array einlesen, es dort mit einem der Algorithmen für Arrays (z.B. QUICKSORT) sortieren und anschließend sortiert als File speichern. Jedoch existieren Anwendungsfälle, in denen die Datengröße die Hauptspeicherkapazität bei weitem übersteigt. Dann muß man auf die sogenannten externen Sortierverfahren ausweichen, die z.B. in [2] (s. Anhang E) beschrieben werden.
Eine der einfachsten Methoden zur Sortierung eines Files heißt Natürliches Mischsortieren. Die Sortierung eines Files C erfolgt dabei in mehreren Durchläufen. Jeder Durchlauf gliedert sich in zwei Schritte:
Bild 79: Natürliches Mischsortieren
Am Beispiel des Programmes in Bild 79 sollen Sie auch lernen, wie man ein fremdes Pascalprogramm liest: Dabei beginnt man am besten am Ende des Listings. Dort steht das Hauptprogramm, das alle Prozeduren aufruft. In diesem Fall wird dort zunächst das File C mit Werten gefüllt, die von der Tastatur eingelesen werden. Ein wichtiges Detail sind auch die Bedingungen, die Repeat- und While- Schleifen kontrollieren. Hier wird die Schleife beendet, falls eine 0 von der Tastatur gelesen wurde. Anschließend wird die Prozedur LIST mit dem File C als Parameter aufgerufen. Bei solchen Prozeduraufrufen haben Sie zwei verschiedene Möglichkeiten, die Funktion des Programmes weiter zu analysieren: Entweder versuchen Sie, die Funktion der Prozedur LIST zu entschlüsseln, oder sie schließen aus dem Namen der Prozedur und dem Kontext auf die Bedeutung des Unterprogrammes.
An dieser Stelle ist es sicherlich einsichtig, daß die Prozedur LIST den Inhalt des Files am Bildschirm auflistet. An diesen Prozeduraufruf schließt sich die eigentliche Sortieroperation (NATURALMERGE) an. Diese Prozedur können Sie wie das Hauptprogramm in einzelne Teilschritte zerlegen.
NATURALMERGE vollzieht die oben beschriebenen Durchläufe in zwei Schritten. Wieder ist die Bedingung der Repeat-Schleife (»UNTIL L=1«) entscheidend. Offensichtlich wird die Variable L in der Prozedur MERGE verändert. Ein Blick auf die Variablendeklaration von L (im Block NATURALMERGE) wird Ihnen jetzt etwas weiterhelfen. Den Rest des Programmes sollten Sie zur Übung selbständig weiter analysieren.
Als eine kleine Hilfe sei noch der Begriff eines Laufes (engl. run) erläutert. Ein Lauf ist eine geordnete Teilsequenz in einem File. So enthält die Folge
(1 4 3 2 7 5 6 8)
diese vier Läufe:
(1 4) (3) (2 7) (5 6 8)
Das Programm MERGE liefert für die obige Zahlenfolge im File C in zwei Durchläufen ein sortiertes File:
C = (1 4 3 2 7 5 6 8) verteile C auf A und B A = (1 4 2 7) B = (3 5 6 8) mische A und B zu C C = (1 3 4 5 6 8 2 7) verteile C auf A und B A = (1 3 4 5 6 8) B = (2 7) mische A und B zu C C = (1 2 3 4 5 6 7 8)
Natürlich können Sie mit dem Algorithmus nicht nur Dateien mit ganzen Zahlen sortieren. Eine Anpassung des Programmes an beliebige Typen erfolgt im Typdeklarationsteil bei den Typen ITEM und KEY.
Eine Erweiterung des obigen Programmes zeigt auch den Sinn zusammengesetzter Datentypen, die Files als Unterstrukturen enthalten. Im sogenannten N-Weg-Mischen werden statt der zwei Hilfsfiles (A und B) insgesamt N verschiedene Files vom Typ TAPE benutzt. Um auf jedes File mit einem Index zuzugreifen, kann man zum Beispiel die folgende Deklaration eines Arrays von Files benutzen:
CONST N = 4; (* Anzahl der Hilfsdateien *)
TYPE TAPENUMMER = 1..N;
TAPE = FILE OF INTEGER;
VAR F : ARRAY [TAPENUMMER] OF TAPE;
F0 : TAPE;
COMMAND: FILE OF CHAR;
I,J : TAPENUMMER;
L : INTEGER; (* ANZAHL DER LÄUFE *)
Verwendet man diese Variablenvereinbarungen, so läßt sich die Verteilung (distribute) des Files F0 auf F[1] bis F[N] folgendermaßen programmieren:
FOR I:= 1 TO N DO
BEGIN
OPEN(COMMAND,'S0:HELP' + CHR(I+64)); CLOSE(COMMAND);
OPEN(F[I],8,2+I,'HELP' + CHR(I+64) + ',SEQ,WRITE')
END;
OPEN(F0,8,2,'SORT,SEQ,READ'); GET(F0);
J:= N; L:=0;
REPEAT
IF J = N THEN J:=1 ELSE J:= J+1;
(* kopiere einen Lauf von F0 auf das Band j *)
L:= L+1;
REPEAT
F[J]^:= F0^; PUT(F[J]); GET(F0);
UNTIL (F[J]^ > F0^) OR EOF(F0);
UNTIL EOF(F0);
CLOSE(F0);
FOR I:= 1 TO N DO CLOSE(F[I]);
Bild 80: Verteilung eines Files auf N Files
Zunächst wird der Inhalt der N Files F[I] gelöscht. Anschließend werden die Files zum Schreiben eröffnet. Um die 4 Dateien unterscheiden zu können, werden sie folgendermaßen benannt:
HELPA HELPB HELPC HELPD
Außerdem erhalten sie mit dem Ausdruck 2 + I eindeutige Sekundäradressen (3, 4, 5 und 6). Nachdem das File F0 zum Lesen eröffnet wurde, werden anschließend solange Läufe von F0 reihum auf F[1], F[2], F[3], F[4], F[1], F[2], ... verteilt, bis das Dateiende von F0 erreicht wurde (EOF(F0) = TRUE).
Durch die Verwendung der OPEN- und CLOSE-Routinen wird zwar ein Programm in Pascal 2.0 etwas länger als im report definiert, jedoch können Sie gezielt (wie in BASIC) auf die Peripheriegeräte des C-128 (Floppy, Datasette, Plotter, Modems etc.) zugreifen, da das Konzept der Geräteadressen und Sekundäradressen voll unterstützt wird. Die Wirkung der vordefinierten File-Prozeduren und Funktionen wird in der Dokumentation (Abschnitt 4.4.5) exakt beschrieben. Im dritten Kapitel werden zusätzlich konkrete Beispielprogramme aufgeführt.
Aufgaben
1. Ändern Sie das Prgramm MERGE in Bild 79, so daß ein File mit Namen und Geburtsdatum sortiert wird:
TYPE ITEM = RECORD
KEY : STRING[20];
G : RECORD
T: 1..31;
M: 1..12;
J: INTEGER
END;
END;
2. Kombinieren Sie die Algorithmen der Programme MERGE und QUICKSORT: Vereinbaren Sie ein Array konstanter Größe (z.B N Elemente) im Hauptspeicher. In diesem Array nehmen Sie eine Vorsortierung des Files C in sortierte Teilsequenzen der Länge N vor. Anschließend können Sie diese Sequenzen durch Natürliches Mischsortieren zu einem einzigen sortierten File C zusammenfassen.
3. Programmieren Sie das skizzierte N-Weg-Sortieren. Beachten Sie dabei die Hinweise zu Bild 80 bezüglich der Vergabe eindeutiger Namen und Sekundäradressen!
4.Um große Datenbestände, die auf sequentiellen Files gespeichert werden müssen, zu erweitern und zu modifizieren, verwendet man in der kaufmännischen Datenverarbeitung folgendes Verfahren:
Eine nach einem Schlüssel (z.B. Kontonummer) sortierte Bestands-Datei wird mit einer nach demselben Schlüssel sortierten Bewegungs-Datei zu einer (ebenfalls sortierten) neuen Bestandsdatei fortgeschrieben. Man muß also alle Änderungen, die man am Bestand vornehmen will, in einer Bewegungsdatei sammeln:
TYPE STAMMRECORD = RECORD
KNUMMER : INTEGER;
NAME : STRING[30];
...
KONTOSTAND: REAL
END;
BEWEGUNG = RECORD
KNUMMER : INTEGER;
UMSATZART : (EIN, AUS, KONTOAUFGABE);
WERT : REAL
END
VAR ALT, NEU : FILE OF STAMMRECORD;
BEW : FILE OF BEWEGUNG;
Während man von der Datei ALT Daten nach NEU kopiert, prüft man, ob für die gerade bearbeitete Kontonummer Umsätze im File BEW vorliegen. Diese werden dann mit dem Kontostand verbucht.
Schreiben Sie ein solches Fortschreibungsprogram, das auch mehrere Transaktionen in der Bewegungsdatei pro Konto erlaubt. Wenn es Sie mehr motiviert, können Sie mit diesem Verfahren auch Adreß-, Schallplatten-, und Literaturdateien verwalten.